課程

2020/07/30
文字探勘
jieba斷字
由於中文語言特性,句子是由字元組成,中文句子之間才有標點符號分隔,不像英文每個詞之間有空格分開,因此中文文字分析必須先經過斷詞處理。
斷詞方法主要有三種:
1.詞庫式斷詞法(jieba、中研院中文斷詞系統)
詞庫:維基百科、現代漢語平衡資料庫…
2.統計式斷詞法(n-gram)
計算字詞出現的條件機率,找出最好的句子結構。不需要詞庫,可依文本結構自行更新
3.混和式斷詞法
本篇會以jieba斷詞作為示範,因為jieba套件在python語言環境中使用方便,並且可以加入自定義辭典。
一、jieba斷詞介紹
1.基於詞庫(字典)建立tier樹
2.將詞與tier樹比對建立有向無環圖DAG
e.g.我聽見雨滴落在青草地 *
0 1 2 3 4 5 6 7 8 9
生成的DAG : { 0:[0], 1:[1,2], 2:[2], 3:[3,4], 4:[4], 5:[5], 6:[6], 7:[7,8,9], 8:[8,9], 9:[9] }
DAG組合也就是{我/聽見/見/雨滴/滴/落/在/青草地/草地/地}
3.取出最大概率DAG
4.以HMM模型尋找新詞
二、jieba斷詞模式介紹
(1)在Anaconda Prompt或命令提示字元輸入:
pip install jieba
(2)匯入套件

(3)實作分詞
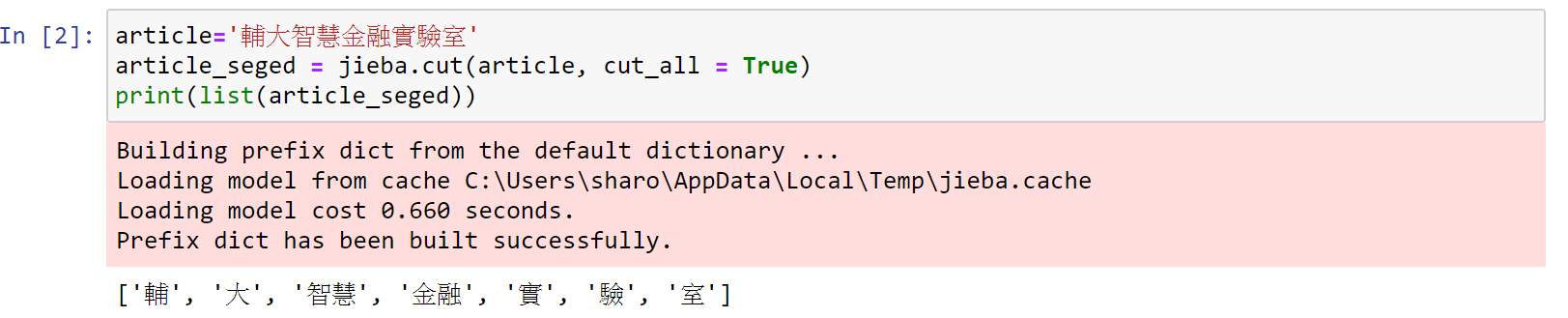
用'輔大智慧金融實驗室'這個句子分詞,可以設定2種分詞模式
a.全模式分詞
利用jieba.cut()斷字
cut_all = True 設定全模式分詞
全模式就是把句子中,可以分詞的組合都列出來
b.精確模式
利用jieba.cut()斷字
cut_all = False 設定精確模式分詞
精確模式就是最精確的把句子切開

三、自定義分詞函式
將函式命名為seg_article。
利用jieba精確模式斷詞。
stopwords是第8節會載入停用詞的txt檔案,如果要分析的文本有廣告或雜訊時,可以將字詞放入txt檔案,這樣就不會干擾分析出的結果。
斷詞後的字詞利用迴圈與停用詞比對,如果文本中沒有stopwords(停用詞),才會存入outstr。
最後第8節會利用這個函式將結果跑出。
