課程

剛剛第三節運用Request套件取得了HTML文件,接下來要解析網頁原始碼,藉由標籤來獲取我們想要抓取的內容,利用BeautifulSoup套件解析網頁原始碼,並以抓取新聞標題及發布時間來說明。
程式碼為: BeautifulSoup(網址變數,'指定剖析器'),其中,網址變數為要解析的HTML文件,也就是上一步驟存入的resp變數。而常用剖析器有html.parser、lxml,而lxml剖析器速度較快,但容錯性也較差。
一、安裝套件
在Anaconda Prompt或命令提示字元輸入:
pip install BeautifulSoup4
二、匯入套件

三、BeautifulSoup套件
用BeautifulSoup套件解析網頁原始碼
程式碼為: BeautifulSoup(網址變數,'指定剖析器'),其中,網址變數為要解析的HTML文件,也就是上一步驟存入的resp變數。
而常用剖析器有html.parser、lxml,而lxml剖析器速度較快,但容錯性也較差,所以這邊是以html.parser舉例。不過,大家可以自行嘗試不同剖析器。

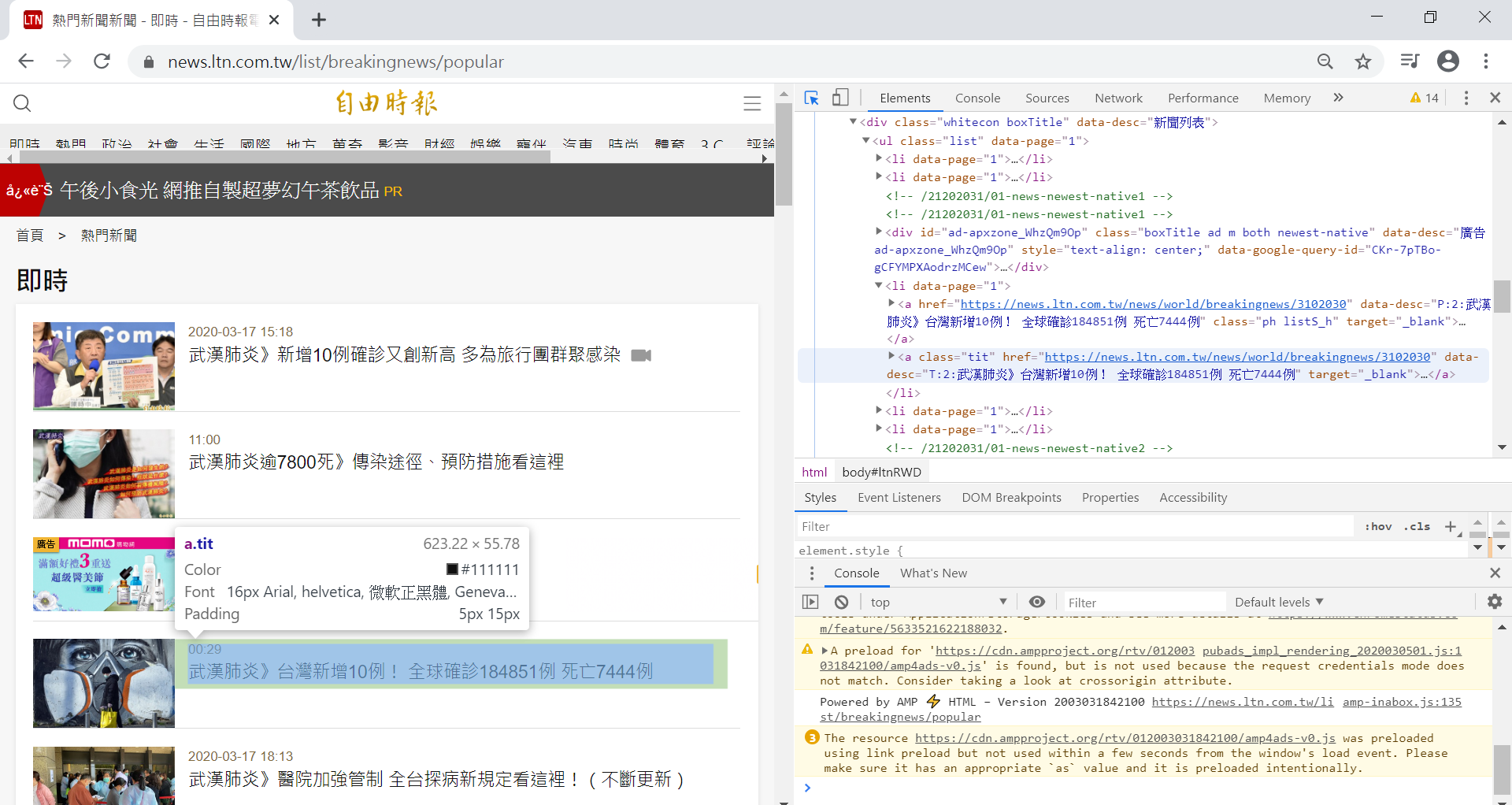
四、找尋要抓取目標所在標籤
(1)開啟目標網頁按F12鍵,查看網頁原始碼
(2)按下箭頭圖案或ctrl+shift+c快捷鍵
(3)游標移至左邊網頁想抓取內容上,會看到右側網頁原始碼移至想抓取目標的標籤上
圖1、按F12鍵,顯示右側網頁原始碼
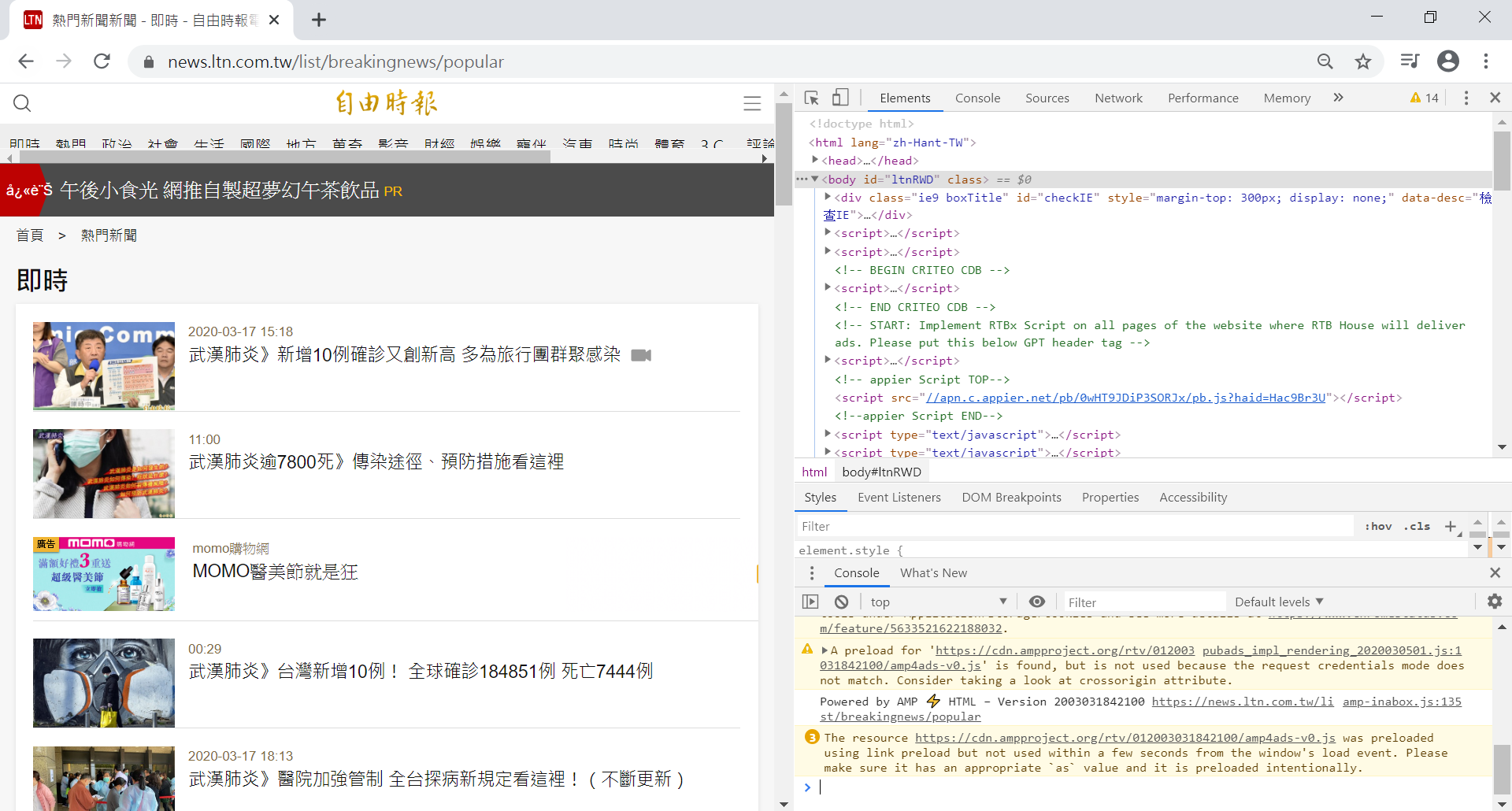
圖2、按下紅框處的箭頭圖案或按下ctrl+shift+c快捷鍵,點選抓取內容位置,以顯示目標內容所在之標籤
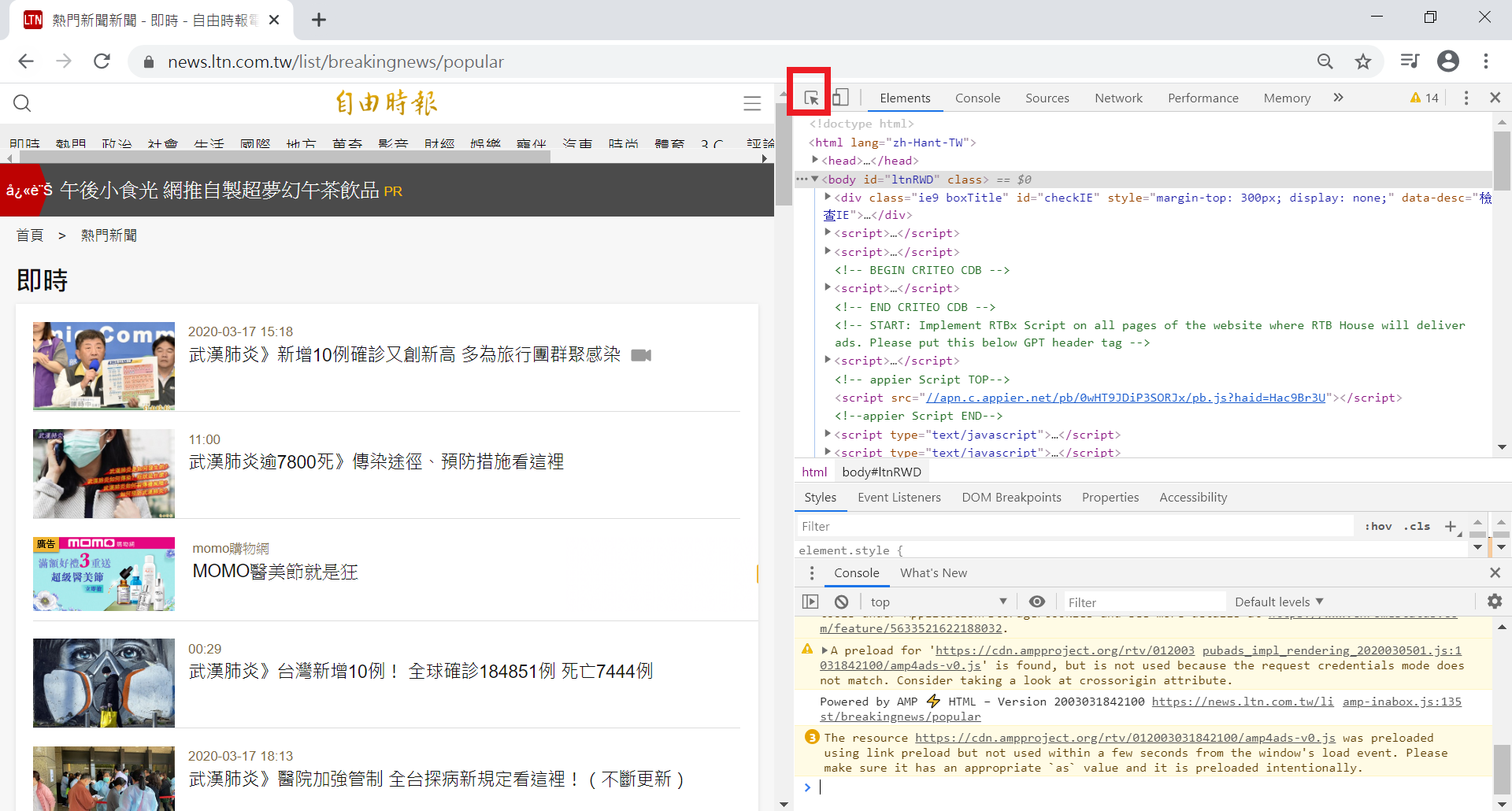
圖3、因為要抓取每則熱門新聞的標題,先查看即時新聞所在的區塊,下方圖中右側網頁原始碼顯示在ul標籤,屬性為list
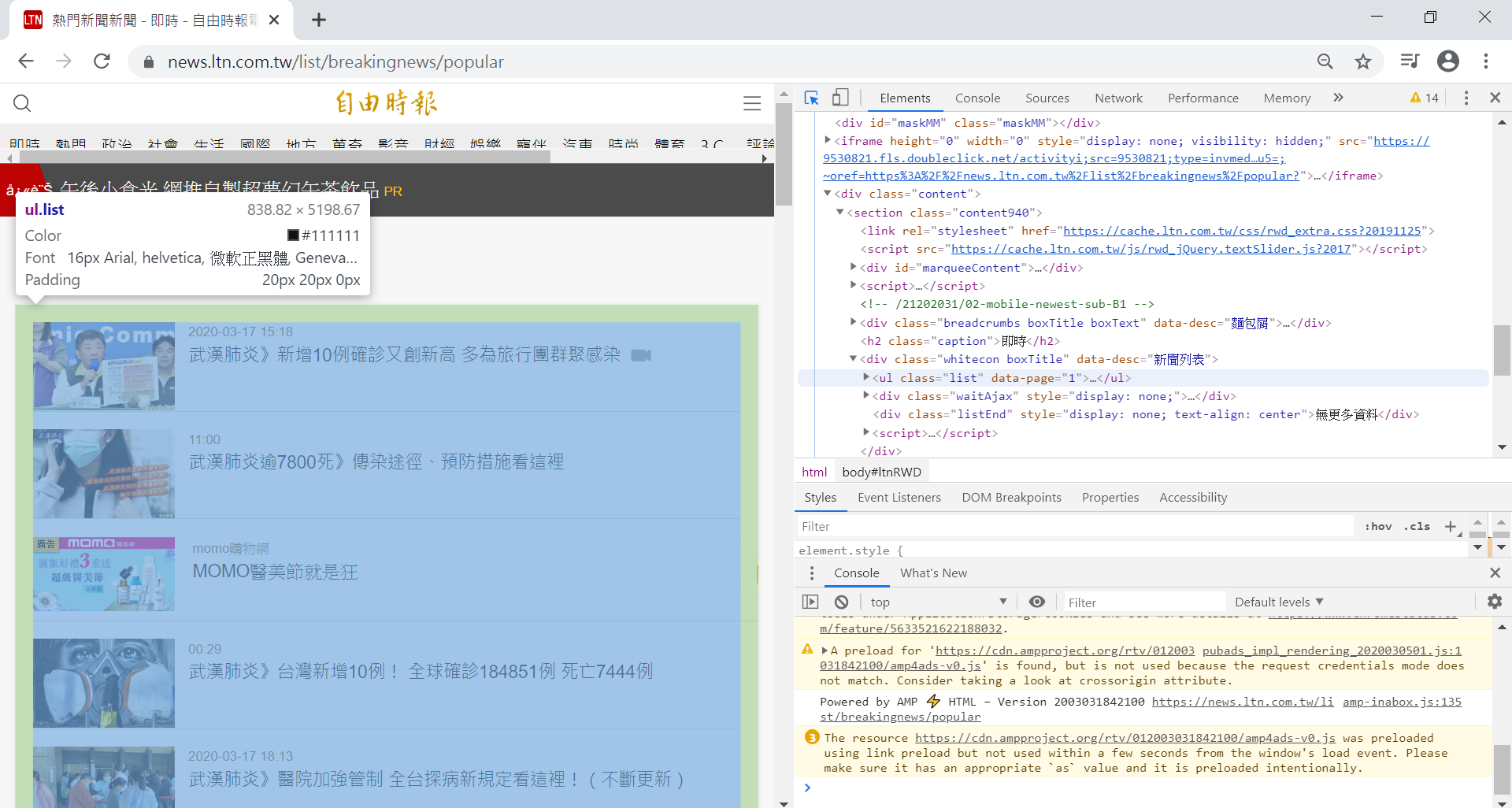
圖4、每一則新聞在li標籤中
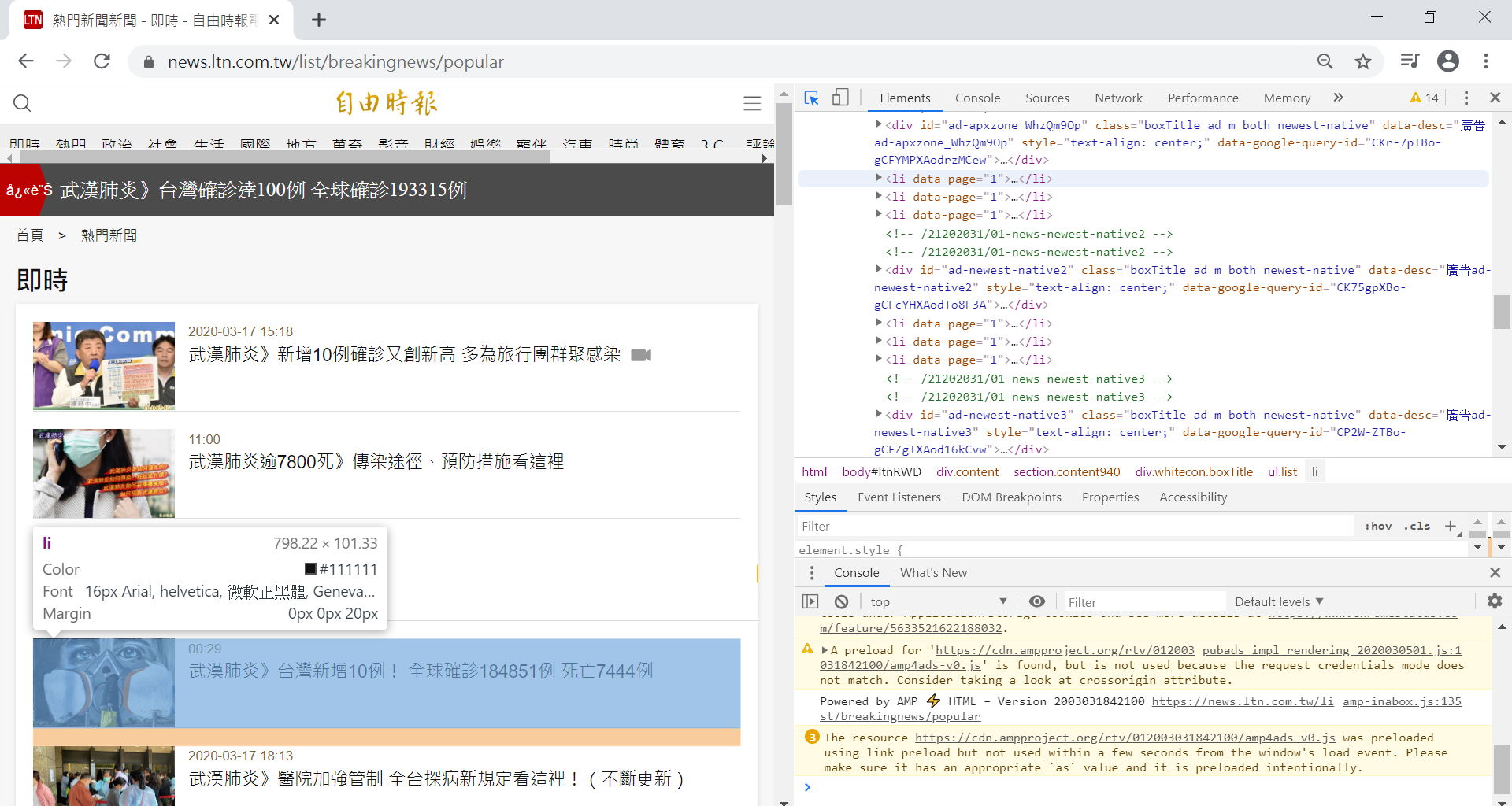
圖5、每則新聞的標題與時間在a標籤,屬性為tit
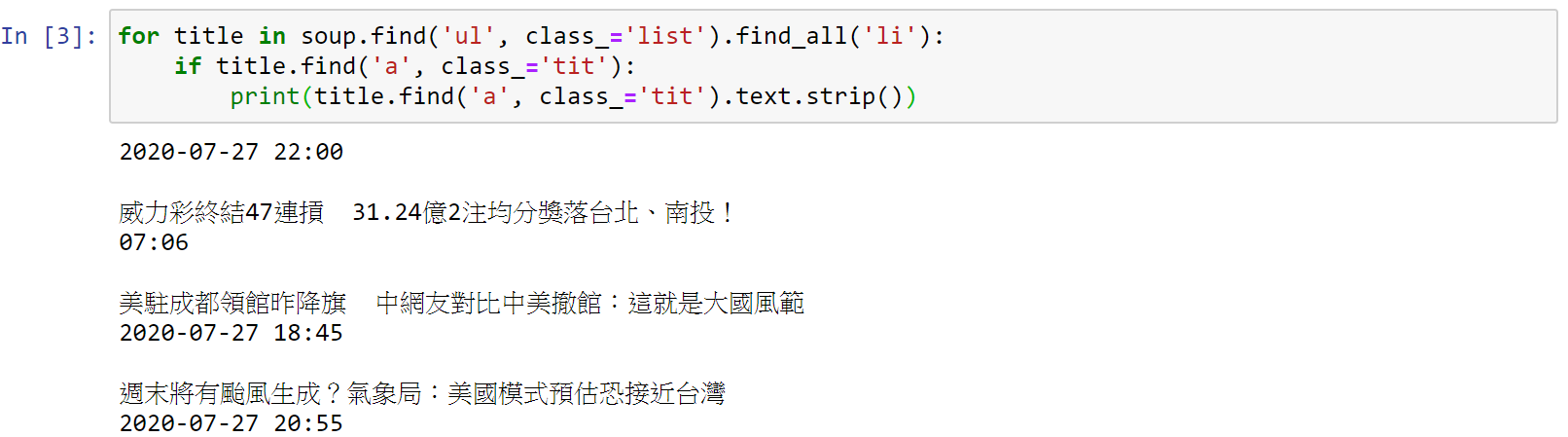
五、利用迴圈及BeautifulSoup套件,得到新聞標題及時間
find()功能只會找到第一個指定標籤
find_all()功能會找到所有指定標籤
利用迴圈,先找到即時新聞所在區塊,再取得每則新聞標籤,最後抓出新聞標題及時間
完整程式碼