課程

2020/04/28
文字探勘
Request套件介紹
撰寫爬蟲程式的套件有很多,這邊先介紹基礎的requests套件。想執行爬蟲的網站稱為目標網站,利用Rquest套件,將目標網站的網址作為參數,套件會發送請求給server,server回傳網頁的response,來完成下載HTML文件的任務。
有了HTML文件再進行解析,以取得我們需要的內容,第四節會介紹用於解析網頁文件的BeautifulSoup套件。
接下來將以抓取自由時報網站新聞標題及發布時間,來說明Request套件的使用。
一、安裝套件
在Anaconda Prompt或命令提示字元輸入:
pip install requests
二、匯入套件

三、requests套件
利用requests套件中requests.get()功能,放入要抓取的目標網址,存入變數,變數可以自己命名,下方命名為resp。想要看到requests套件回傳的結果,可以印出resp變數,查看回傳的HTML文件。
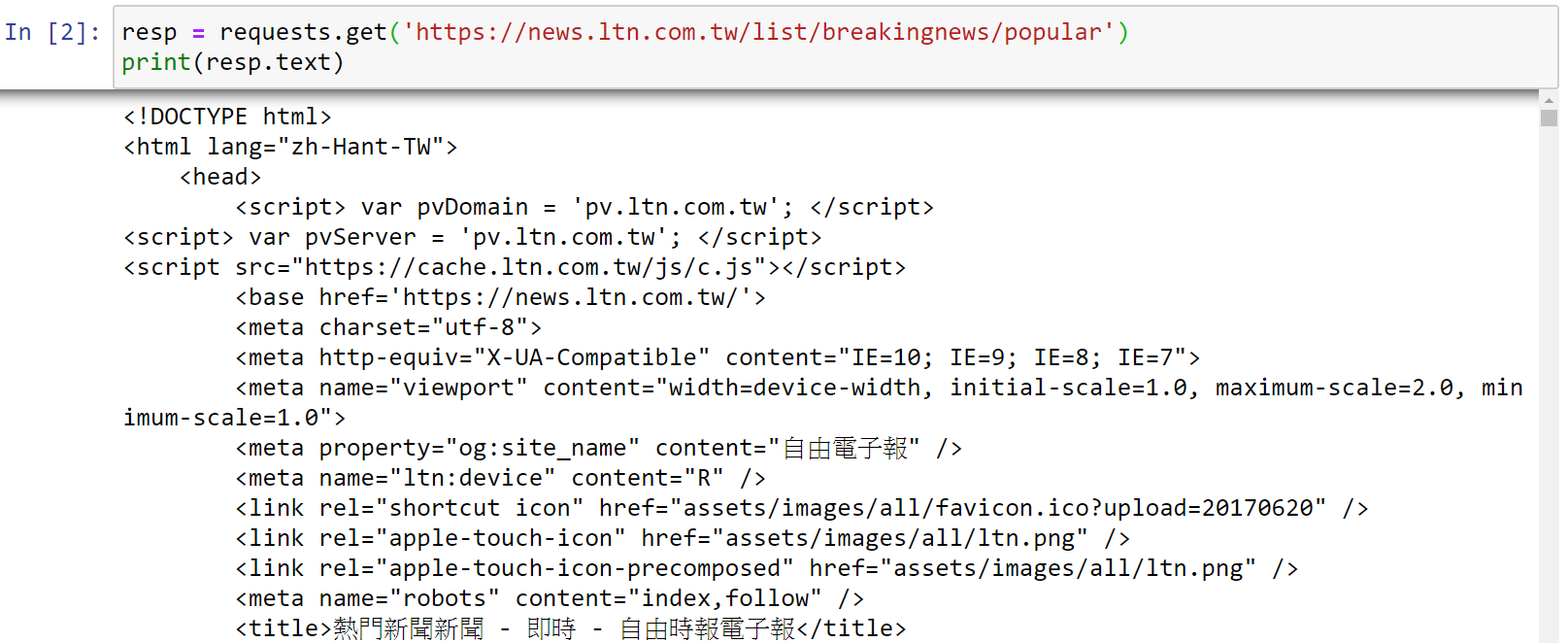
完整程式碼