課程

本章將介紹文字分析的資料預處理部分,主要內容為:
1.讀入文本檔案
2.建立今日新聞
3.透過正則表達式,將數字、英文及符號替代掉
將上述三點的程式碼自定義為Data_preprocessing函式,最後第8節會利用這個函式將結果跑出。
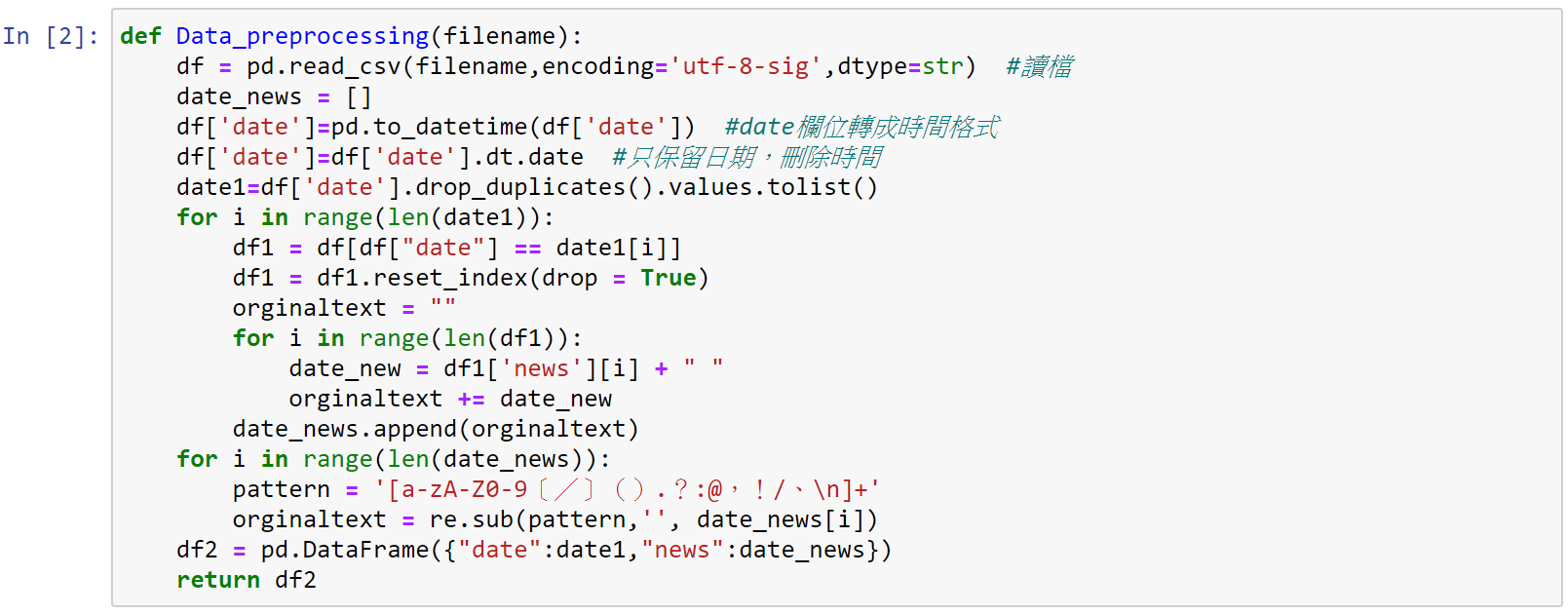
一、讀入檔案
程式碼為: df = pd.read_csv(filename,encoding='utf-8-sig',dtype=str) #讀檔
filename在第八章會定義為要分析的資料集,所以這邊的檔案路徑不需更改
二、建立今日新聞
先觀察分析的資料集,詳見下圖1、圖2
圖1、讀入資料集,將日期欄位轉成python的時間格式,再print出資料集前10筆資料

圖2、前十筆資料,可以看出2020-01-01的新聞會有多筆

另一種觀察資料的方法,可以利用groupby()分組,.count()可以得知各組的數量,可以觀察到每日有幾則新聞。詳見圖3
圖3、利用groupby().count()觀察各日的新聞數量

由於之後的萃取關鍵字、情緒分析都是以日期為單位,例如一天算一個情緒分數。因此這一節需先將新聞做預處理,當日的不同新聞,以空格連接起來。也就是說,一日只會有一筆資料,一月有31天,總共就有31筆資料。
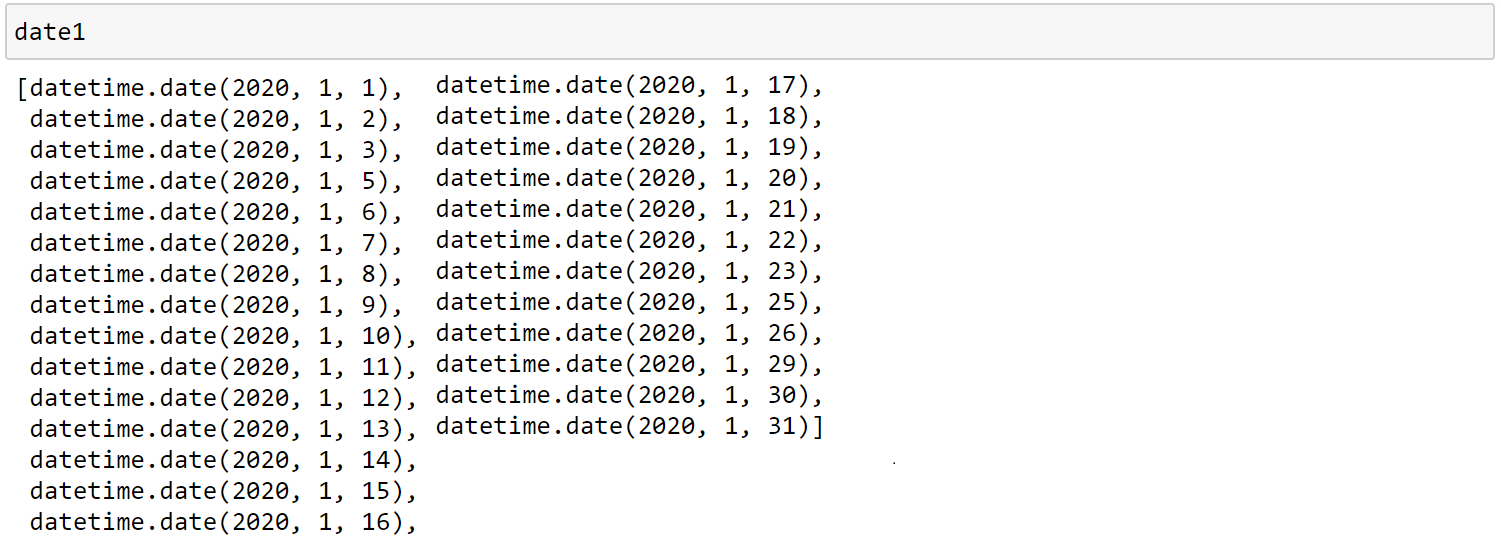
date1=df['date'].drop_duplicates().values.tolist(),將df中的date欄位,移除重複項,也就是一個日期只會有一項。
圖4、date1結果
剛剛建立的date1,利用迴圈依序抓出當日新聞為df1,再把df1中的新聞以空格連接起來,存入date_news
for i in range(len(date1)):
df1 = df[df["date"] == date1[i]]
df1 = df1.reset_index(drop = True)
orginaltext = ""
for i in range(len(df1)):
date_new = df1['news'][i] + " "
orginaltext += date_new
date_news.append(orginaltext)
三、正規表示法
由於是做中文的文字分析,要先將文本當中非中文的部分刪除,所以利用正規表示法,建立字串篩選的規則,pattern = '[a-zA-Z0-9〔/〕().?:@,!/、\n]+',a-zA-Z0-9在正規表達式為數字及英文大小寫,再利用re.sub(pattern,'', date_news[i]),將先前定義的pattern(數字、英文大小寫、符號)替換掉,也就是刪除新聞中的數字、英文大小寫、符號。
想要更了解正規表示法,可以參考下方官方文件介紹: