課程

本文將介紹利用Keras的套件搭建LSTM模型並進行股價的預測
(1)主題:利用前5天資料預測下一天的收盤價(Many to one)
(2)資料:台積電股票資料(2007/7/17~2019/3/13)
(3)特徵變數:開盤價、最高價、最低價、收盤價、5MA、20MA和60MA
(4)目標變數:隔天收盤價
一、首先,先匯入需要的Python套件
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
import keras
import matplotlib.pyplot as plt
二、讀入資料、資料預處理 將資料以正規化處理,避免讓數值大的特徵影響訓練結果
df = pd.read_csv('2330.csv', encoding='cp950')
dataset = df.dropna()
sc = MinMaxScaler()
data = sc.fit_transform(dataset)
三、製作訓練資料與測試資料
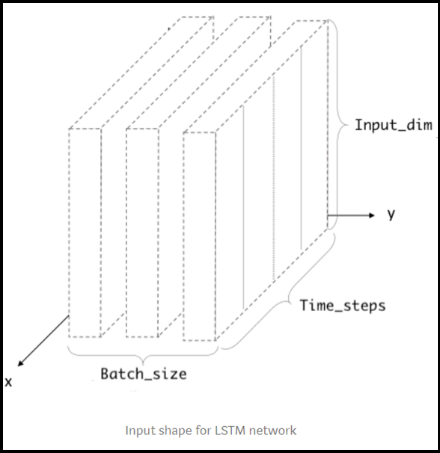
LSTM測試資料的製作與一般機器學習不同,所以無法單純的把資料進行切分建模。LSTM 輸入的資料必須符合三個維度,形式為(batch size, time steps, Input dimension, 圖2-1),但利用Keras進行模型資料輸入的維度考慮time steps以及Input dimension即可,以本文例子舉例,訓練資料的time steps為5,表示用每5天的資料作訓練;Input dimension 則是7,因為輸入的特徵變數有7個。
製作訓練資料與測試資料的程式碼如下:
其中Sequence length 表示是要用5天的資料進行訓練資料,split pct則表示要用資料的多少百分比作為訓練的資料集,而X資料為(2877, 5, 7),所以用split_pct * X.shape[0]表示訓練資料的筆數,也就是split_pct *2877。
sequence_length = 5
X = []
y = []
index_date = []
# data_x = data.drop(['return'], axis=1)
#利用前五天的features預測隔天收盤
for i in range(0, len(data) - sequence_length):
X.append(data.iloc[i:i + sequence_length].values)
y.append(data['close'].iloc[i + sequence_length])
index_date.append(data.index[i])
X = np.array(X)
print(X.shape)
y = np.array(y)
print(y.shape)
split_pct = 0.7
split_thre = int(split_pct * X.shape[0])
X_train = X[:split_thre, :]
y_train = y[:split_thre]
index_date_train = index_date[:split_thre]
X_test = X[split_thre:, :]
y_test = y[split_thre:]
index_date_test = index_date[split_thre:]
四、建置模型:模型的建置以函數包裝,以方便重複利用
建置模型的第一步為model=keras.models.Sequential(),這裡概念像是替模型建好框架,方便神經模型隱藏層的製作,把它想成是蓋房子的鋼筋架構(框架),才能進行灌漿(設置隱藏層)的動作。接下來開始製作隱藏層,範例中為兩層LSTM以及一層Dense層,Dense層的作用是將所有隱藏層進行連接的動作,在Dense層中kernel_initializer用來在訓練模型前進行神經元權重(weight)的初始化,uniform表示初始化方法是利用均勻分布的機率值決定。
每層的隱藏層都可以設定神經元個數,也就是範例中100這個數字,參數名稱為units=100。第一層的LSTM必須設定input shape,也就是上一個步驟製作訓練資料的維度,即X_train[0].shape,維度為(5, 7);另外,return_sequences是控制此層輸出資料型式的參數,只有在最後一層LSTM設定為False(預設為False),其餘為True。如果return_sequences=True:輸出資料形如(samples,timesteps,output_dim),反之為(samples,output_dim)。
最後,要將模型進行Compile,也就是要將損失函數訓練到最佳,這邊本為選擇mse來當作損失函數,並用Adam方法來進行優化,其中0.0006表示學習率,也就是逼近最佳解的學習速率。優化函數還有隨機梯度下降法等方法。
def build_model():
model = keras.models.Sequential()
model.add(keras.layers.LSTM(100, return_sequences=True,
input_shape=X_train[0].shape))
model.add(keras.layers.LSTM(100))
model.add(keras.layers.Dense(1, kernel_initializer="uniform"))
adam = keras.optimizers.Adam(0.0006)
model.compile(optimizer=adam, loss='mse') model.summary()
return model
五、訓練模型
模型設定完成後,開始訓練資料,先將之前模型函數叫出,再來進行訓練,batch size決定一次訓練的樣本數目,並進行50次的epoch訓練,而1次的epoch代表訓練過一次完整的資料。另外,將20%的訓練資料當作驗證資料以檢視模型訓練的成效。
#creat model
model = build_model()
#Model training
history = model.fit(
X_train,
y_train,
batch_size=50,
epochs=10,
validation_split=0.2)
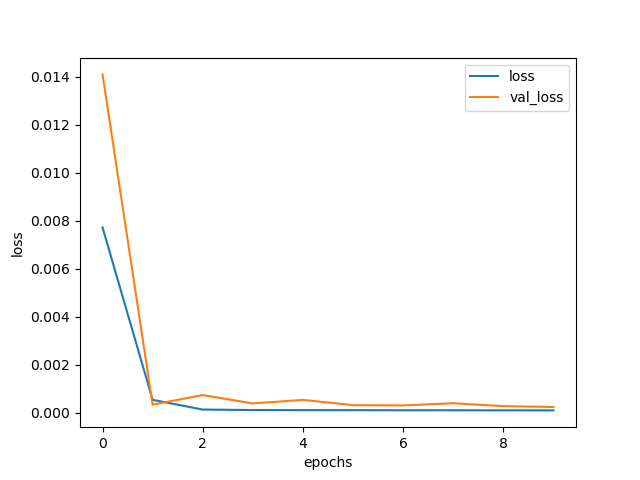
六、畫出訓練資料與驗證資料的誤差
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
將模型訓練出來的結果視覺化,圖中可以看到在epoch=1時損失近0
七、預測
將資料進行預測,並輸出評估結果(scores),此結果代表MSE,因為模型的損失函數(loss function)設定為MSE。
predicted_stock_price = model.predict(X_test)
# model.evaluate 取得 loss 值
scores = model.evaluate(X_test, y_test)
八、還原成真實股價
將正規化後的資料還原成真實的股價, 其中sc.inverse_transform就是是將股價還原的函數方法。
#將實際股價與預測的股價返回原來的值
#create empty table with 12 fields
testPredict_dataset_like = np.zeros(shap(len(predicted_stock_price), len(df.columns)))
trueprice_dataset_like = np.zeros(shape=(len(y_test.T), len(df.columns)))
# put the predicted values in the right field
testPredict_dataset_like[:, 0] = predicted_stock_price[:, 0]
trueprice_dataset_like[:, 0] = y_test.T[:]
# inverse transform and then select the right field
testPredict = sc.inverse_transform(testPredict_dataset_like)[:, 0]
trueprice = sc.inverse_transform(trueprice_dataset_like)[:, 0]
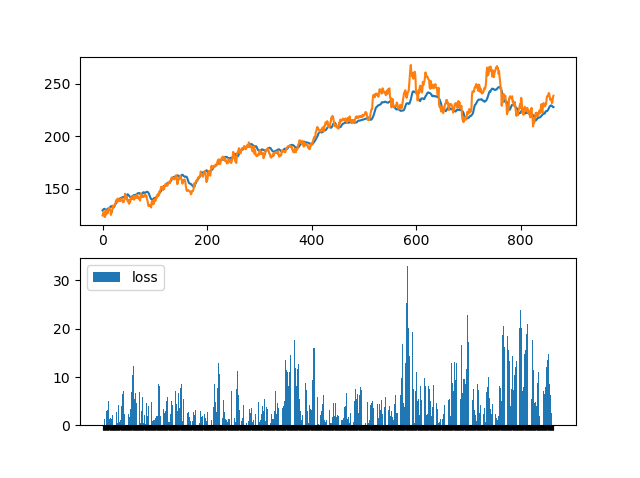
九、結果視覺化
最後一個步驟,將結果以視覺化的方式呈現(圖2-4),藍色為實際走勢,橘色為預測結果,下面那張圖表示真實價格與預測價格的差。以上為利用LSTM的範例進行股價預測。
ax = plt.subplot(2, 1, 1)
ax1 = plt.subplot(2, 1, 2)
ax.plot(testPredict, label='testPredict')
ax.plot(trueprice, label='trueprice')
plt.legend()
ax1.bar(index_date_test, abs(trueprice - testPredict), label='loss')
ax1.set_xticklabels([])