課程

接下來實作演練的部分,會先介紹如何利用程式碼完成一個簡單迴歸模型。
(一) 簡單迴歸:
首先,第一步很重要的是要先「設定讀取檔案的路徑」,簡而言之,就是自己想要放入迴歸模型中的資料,要怎麼讓python知道說,我要用這個資料跑迴歸。
一開始要「看看python預設的檔案讀取路徑在哪裡」,因為自己要跑的資料,可能根本就不是放在那個讀取路徑下面,這個時候就要「改變讀取檔案的路徑」,告訴python說,我現在讀取的資料是在這個新的檔案路徑下。

第二步就是要「讀取資料」了,告訴python說我匯入這個資料來跑迴歸,而這份資料我把它取名為「data」。讀完資料後,可以順便檢視一下自己讀進來的資料長甚麼樣子。
p.s. 這邊實作演練的例子,讀取的檔案資料是2008年到2020年3月華通(2330)的稅前淨利和財務成本的資料。

第三步要開始「定義變數」,就是告訴python說,我要把哪個資料設定成y變數,哪些資料設定成x變數。在這裡我是告訴python說『我的x變數是「data」這份資料中的財務成本那一欄』,y變數也是採用同樣的方法。

第四步要開始「建立迴歸模型」,就是告訴python說,我要用前面告訴你的x和y變數去跑迴歸,並且跑出來的結果,我要叫它「results」。

最後一步就是要「輸出迴歸結果」了,因為前面我們已經將這份資料的迴歸結果,給它取了一個名字了「results」,但是如果只給它取名字,不叫它出來的話,我們是看不到結果的,所以就要「叫它的名字」了。
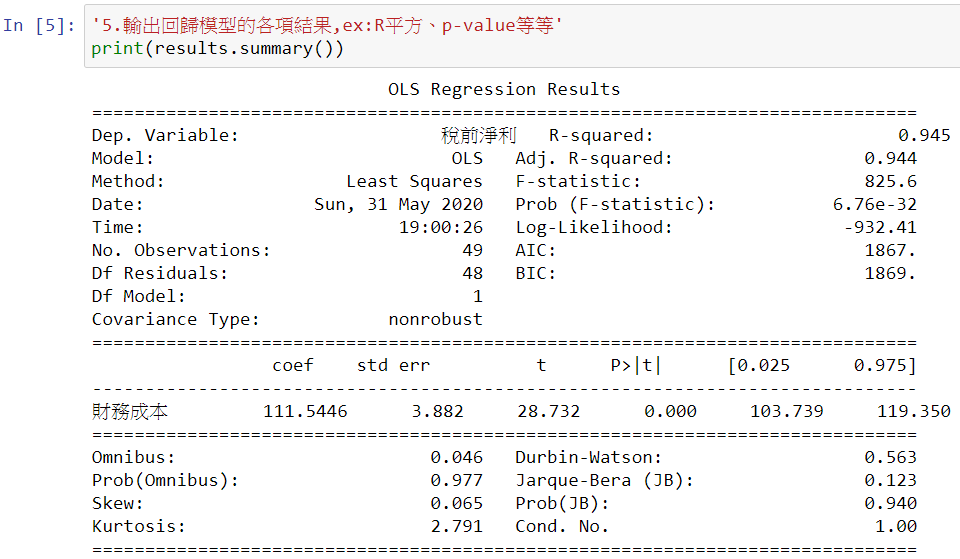
跑出迴歸的結果之後,我們就要來解讀資料了,其中很重要的就是看「R-squared」,告訴我們說這個跑出來的結果好不好,有沒有很強的解釋能力,能說明x和y之間的關係,如果它越靠近1,則代表解釋能力越好。
看完R-squared之後,來看「P>|t|」也就是p-value,告訴我們說x對y的顯著性,若結果小於
p-value也看完了,就來看「coef」也就是相關係數,x和y之間的關係了,看它們是正相關或負相關,相關的程度又有多強。
線性迴歸範例完整程式碼
(二) 複迴歸
到了複迴歸的部分,前面的兩個步驟都跟簡單迴歸的實作演練一模一樣,分別是「設定讀取檔案的路徑」和「讀取資料」。
p.s. 這邊實作演練的例子,讀取的檔案資料是2008年到2020年3月華通(2330)的稅前淨利、財務成本和營業費用的資料。


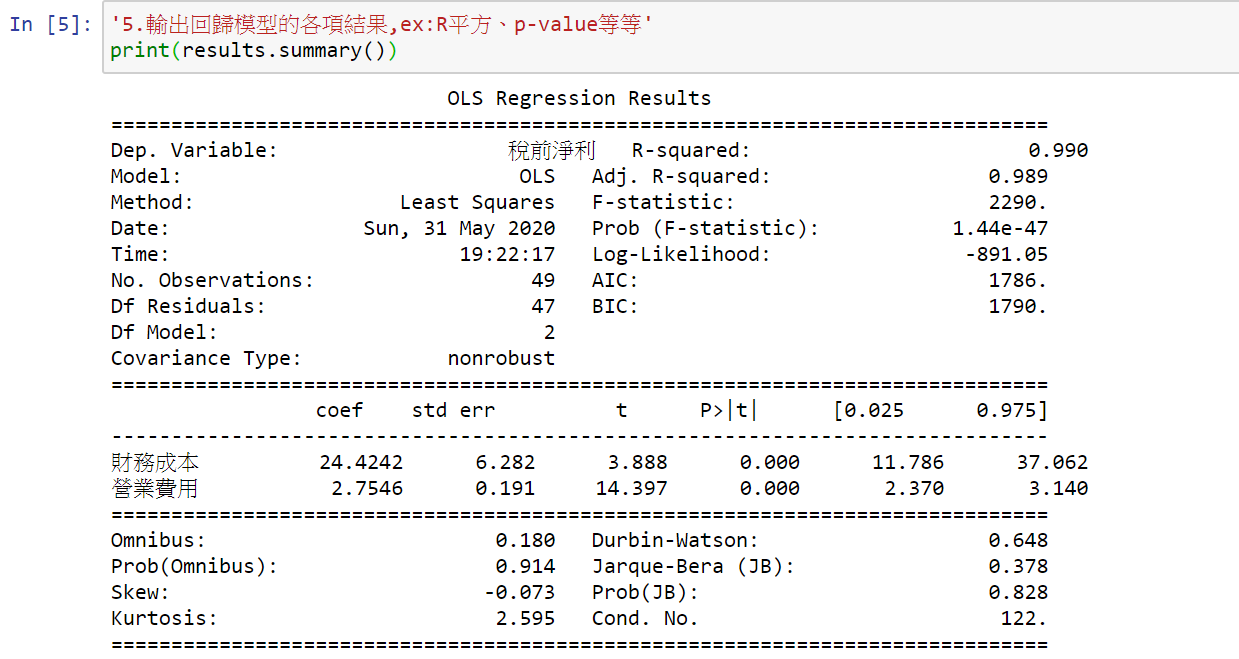
但到了第三步驟「定義變數」,就有一點不一樣了,因為複迴歸要用到的x變數不只一個,這時就要告訴python說『我的x變數有很多個,分別是「data」資料中的哪幾欄』,都是我的x變數。(y變數就同簡單迴歸的方法是一樣的)

後續的步驟就跟簡單迴歸的實作演練是相同的。

複迴歸完整程式碼