課程

2020/08/04
python語法介紹
敘述性統計和相關係數
進行資料分析時,很可能需要分析大量資料,因此可以利用統計的方法迅速的瞭解資料的分布,像是觀察資料的平均數、標準差、最大值、最小值等。
df.mean()
df.std()
df.max()
df.min()
df.drscribe()
一樣利用DataReader套件下載台積電的股價資料作為例子,將下載的股價資料命名為df1
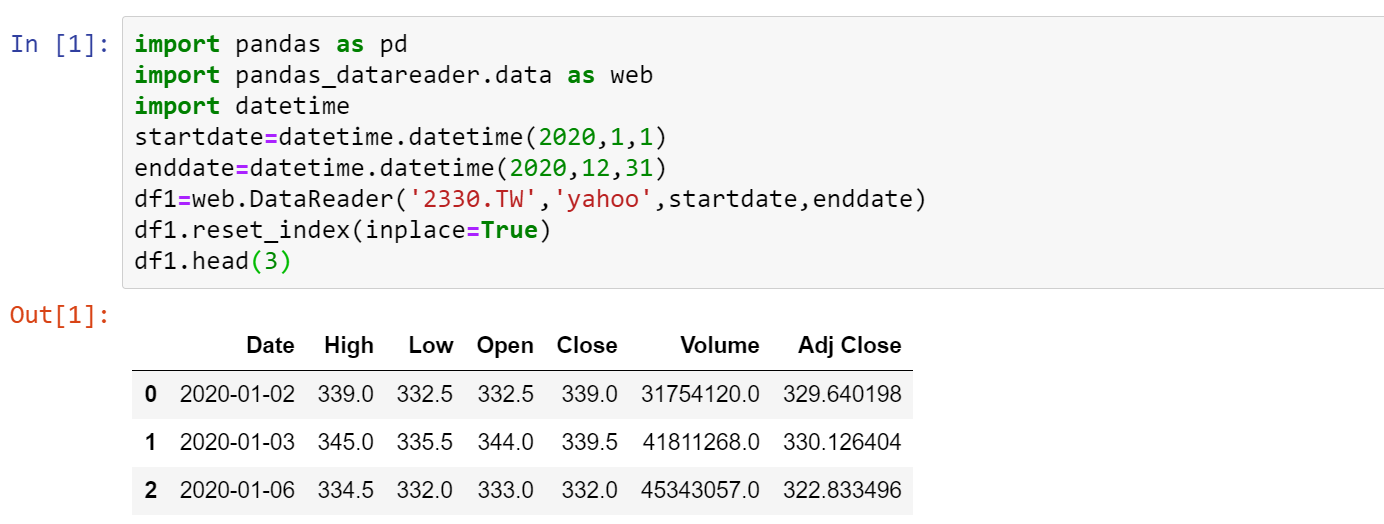
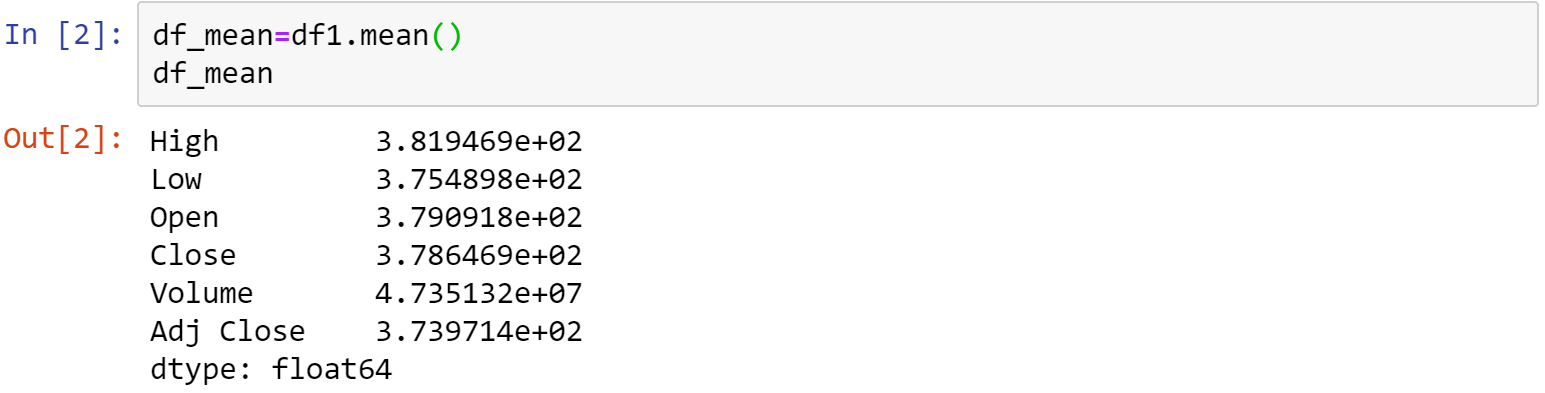
一、平均值
利用.mean()函式,即可印出df1各個column的平均數
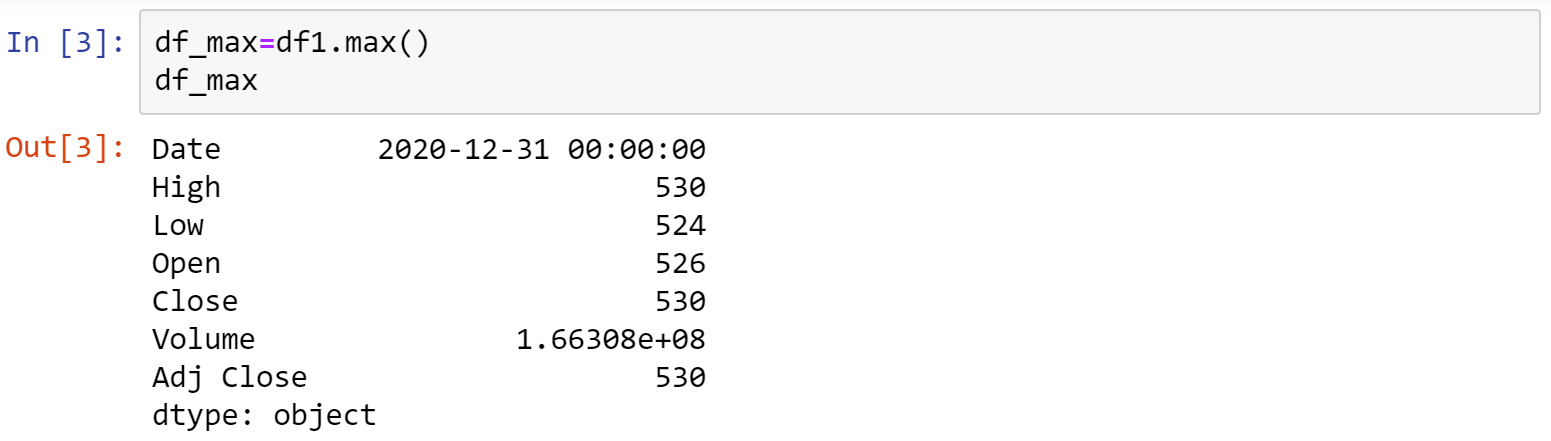
二、最大值
利用.max()函式,即可印出df1各個column的最大值
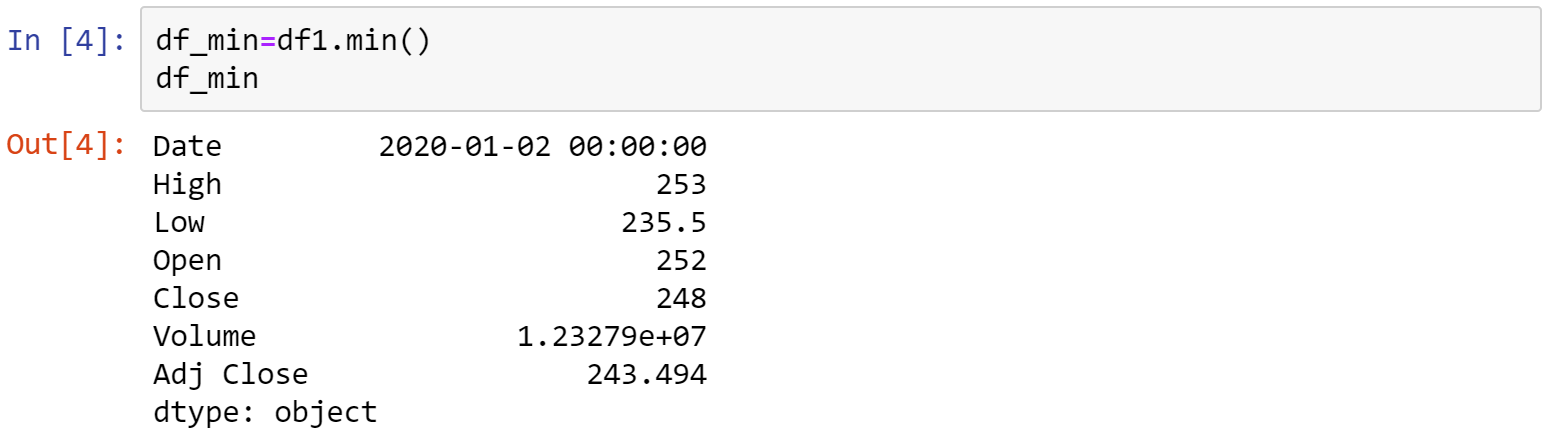
三、最小值
利用.min()函式,即可印出df1各個column的最小值
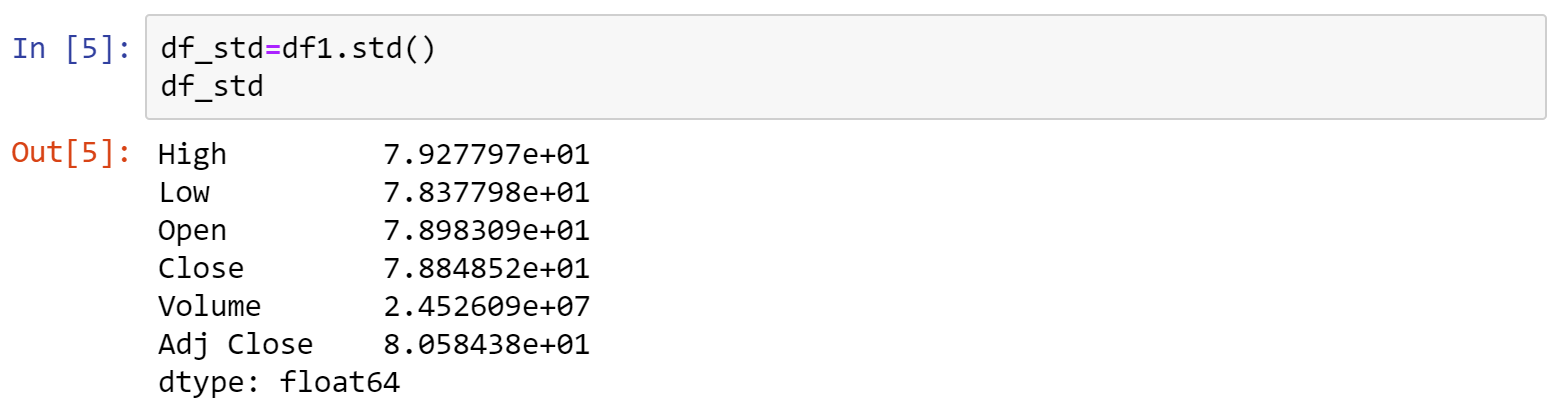
四、標準差
利用.std()函式,即可印出df1各個column的標準差
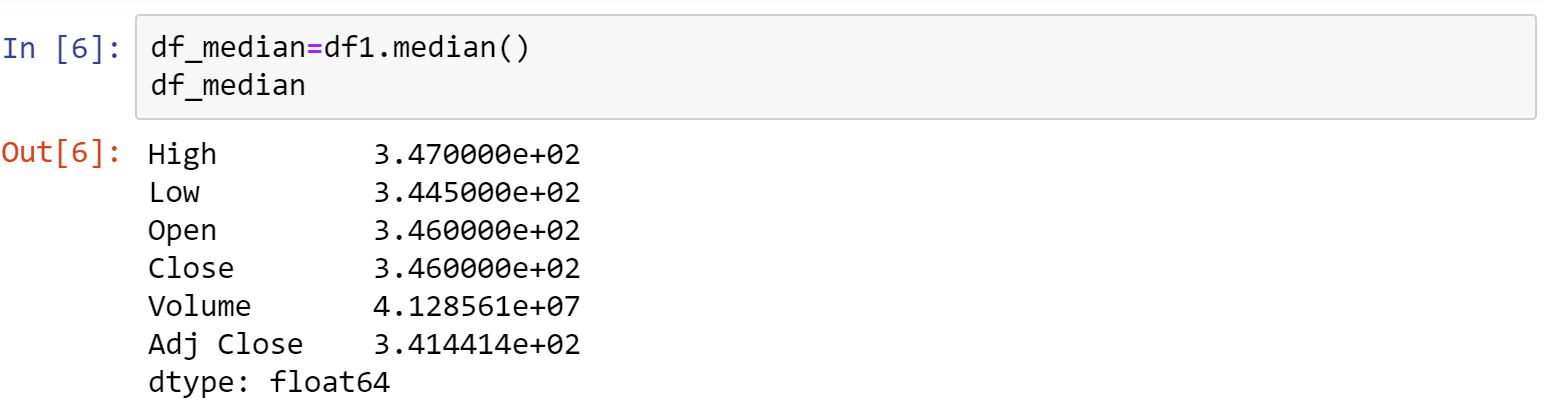
五、中位數
利用.median()函式,即可印出df1各個column的中位數
六、眾數
利用stats.mode()即可印出df1最低價欄位的眾數

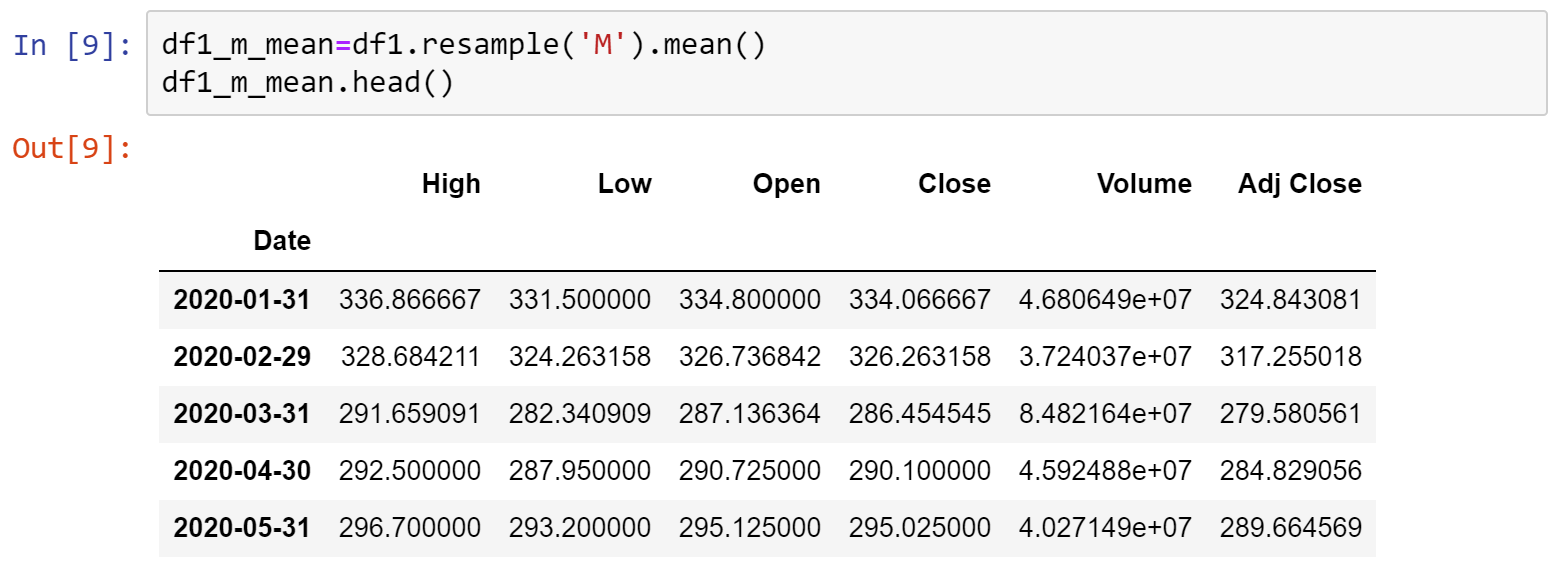
七、求每個月資料的平均
在資料處理時,不一定只需要求一張表格的平均值,有時需要做一些變化,像是取每個月股價的平均,這時可以使用到resample函式,先將資料重塑為每個月再取平均,因此先將重設df1的index,將索引換成時間索引
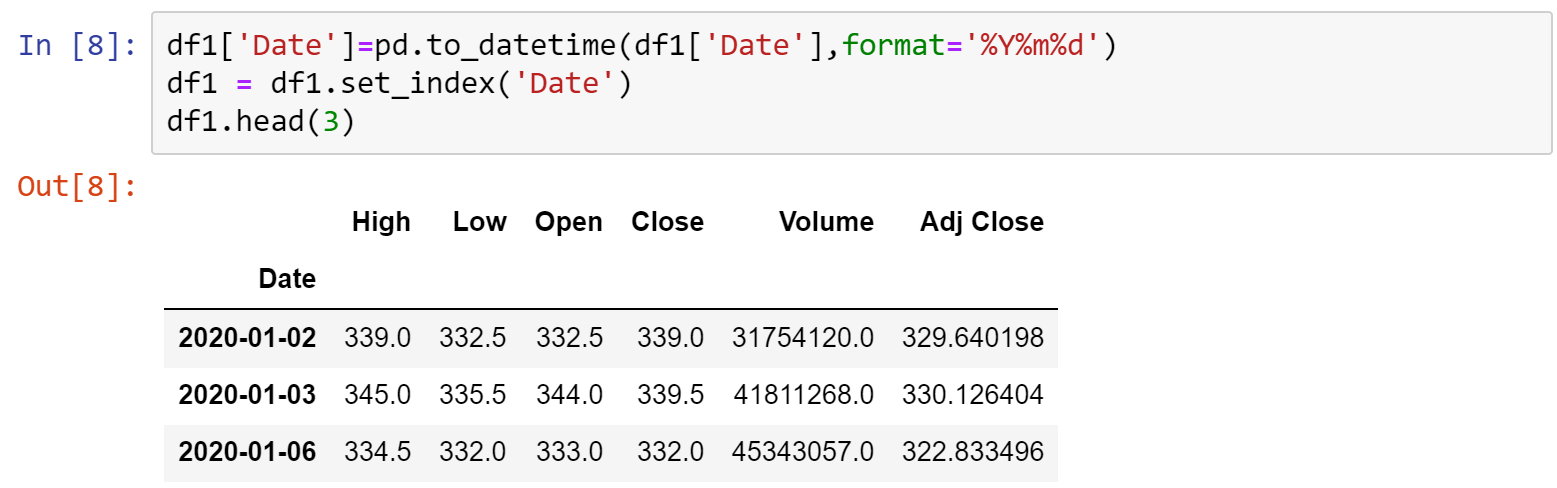
利用resample()函式,參數設為'M',也就是將資料重塑為月,.mean()就是求每個月的平均值