課程

一、簡介
我們回收問卷時得到的原始資料(Raw Data)形式可能五花八門,包括回答是或否的簡答題、回答數值的評分題,甚至非必填的欄位很可能是空白。然而,機器並不能理解文字、圖片或影片。因此,在進行數據分析前,我們應該先把資料整理成機器看得懂的形式,後續才能順利進行建模、分析以及提升模型預測效果,而這個步驟就叫做「資料預處理(Data Preprocessing)」。事實上,這也是整個機器學習流程中最重要且最費時的步驟。
二、資料清理
(a)資料篩選 Data Selection
篩選出欲分析的資料(移除極為相似的、多餘的特徵)或剔除異常資料。
(b)處理缺失值 Missing Values、雜訊資料 Noisy Data (異常值error、極端值outlier)
-刪除(會損失資訊)
-補值: 平均數mean、中位數median、眾數mode、KNN最近鄰插補法
三、特徵工程
(一)資料轉換 Data Transformation (二)特徵編碼 Feature Encoding: 使用於類別型變數 (2)One-Hot Encoding:為目標變數每個類別建立新欄位,若屬於該欄位為1,否則為0。 即使Label Encoding只需要新增一個欄位,但替換後的數字編碼仍屬於類別變數,其數值沒有連續關係;而One-Hot Encoding的目標變數若有太多種類,將會新增很多欄位,則需要更多時間訓練模型。因此,可以使用Target Mean Encoding,這也是一種常見的提升模型績效的方式:
統一單位(時間、距離、金額)
特徵縮放 Feature Scaling: 使用於連續型變數
(a)標準化 Standardization
-以Z-score作為特徵值
-經標準化的資料變成平均值為0、標準差為1的常態分佈
-使離群值的影響降低
(b)歸一化、正規化 Normalization
-等比例縮放,數值通常介於0~1之間
-Min-Max Normalization
(基於空間距離去學習的演算法,會受到數值較大、範圍較廣的特徵影響)
機器學習模型無法處理文字,因此須以數值編碼取代原始以文字形式出現的類別變數(血型、國家、職業)。假設今天我們要研究居住地與身高是否有關聯,而發放問卷得到的原始資料如下:
RAW DATA
City
Height(cm)
0
New Taipei City
156
1
Taipei City
170
2
Taoyuan City
180
3
Taipei City
165
4
New Taipei City
176
5
Taoyuan City
160
機器無法判斷城市名稱,因此需進行數字編碼,以下將介紹三種不同的編碼方式:
(1)Label Encoding:以數字編碼取代原始資料的文字。
City
Height(cm)
City_Label
0
New Taipei City
156
1
1
Taipei City
170
2
2
Taoyuan City
180
3
3
Taipei City
165
2
4
New Taipei City
176
1
5
Taoyuan City
160
3
City
Height(cm)
New Taipei City
Taipei City
Taoyuan City
0
New Taipei City
156
1
0
0
1
Taipei City
170
0
1
0
2
Taoyuan City
180
0
0
1
3
Taipei City
165
0
1
0
4
New Taipei City
176
1
0
0
5
Taoyuan City
160
0
0
1
(3)Target Encoding:對該類別所有樣本的目標變數統計量進行數字編碼,均值編碼(Mean Encoding)較常見。
City
Height(cm)
Height_TargetMean
0
New Taipei City
156
166
1
Taipei City
170
167.5
2
Taoyuan City
180
170
3
Taipei City
165
167.5
4
New Taipei City
176
166
5
Taoyuan City
160
170
四、範例
接下來,我們用Kaggle的「信用卡違約繳款客戶資料集 Default of Credit Card Clients Dataset」來做練習。下方連結可進入kaggle網站進行下載。
此資料集是台灣2005年4月到9月的30,000筆信用卡客戶資料,共有25個特徵變數,其中包括:違約繳款紀錄、人口統計變數、信用資料、歷史繳款紀錄以及信用卡帳單。
首先,讀入pandas套件與信用卡違約繳款客戶資料集之csv檔。

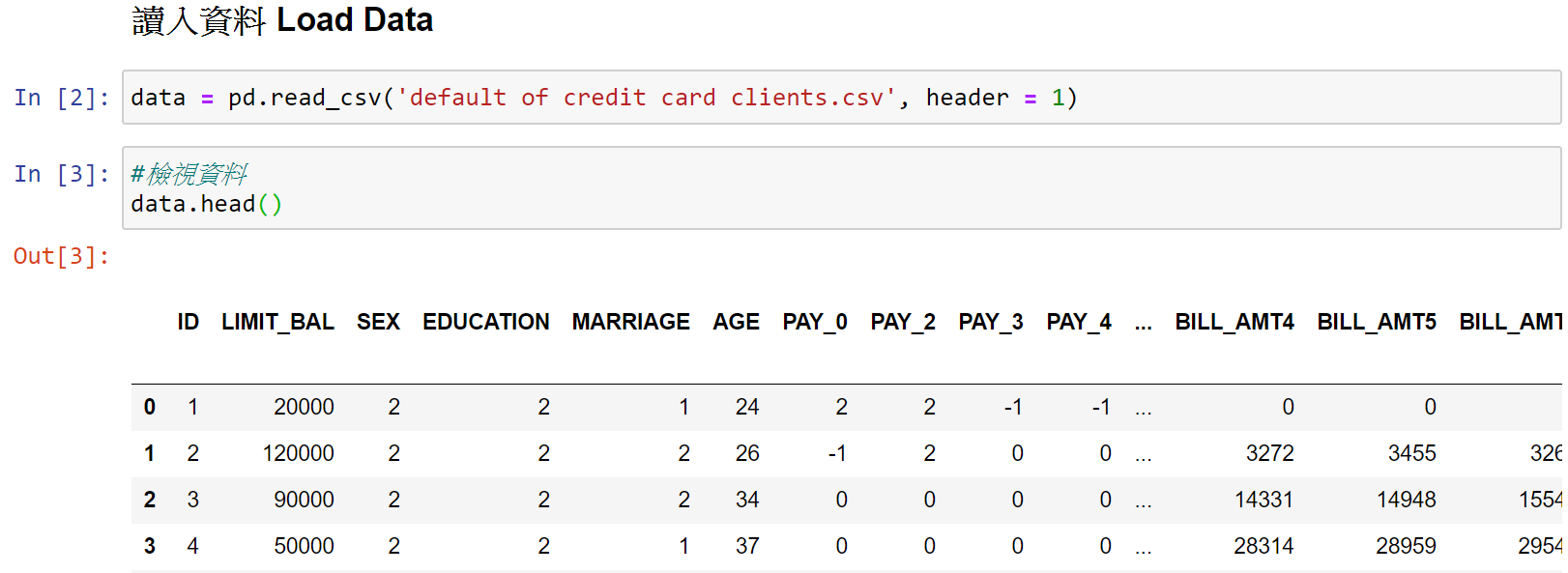
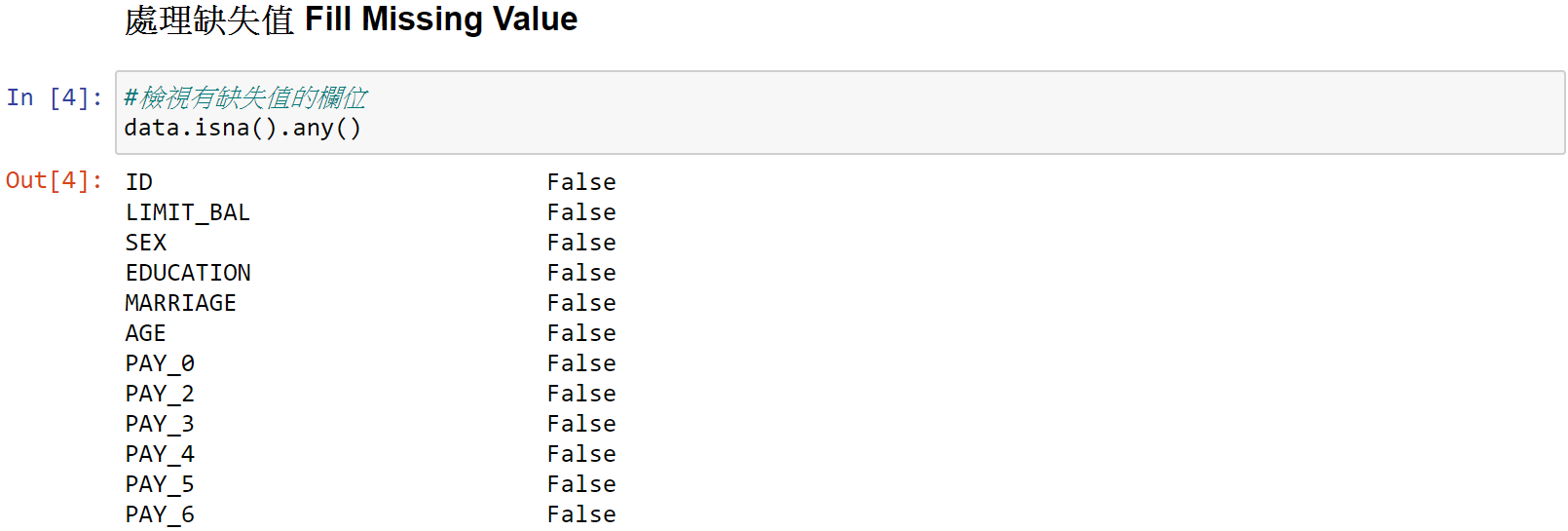
(1)資料清理
由於此資料集很乾淨整齊,因此僅簡單示範2種填補缺失值的方法。

(2)特徵縮放
為避免模型受到數值較大、範圍較廣的特徵影響,可以將這些特徵做縮放。

而此資料集已完成Label Encoding,因此不需再做處理。
(3)特徵編碼

對[婚姻]欄位做One_Hot Encoding,依其值0-3,共生成4個新特徵。

最後,分別對[教育]各類別所有樣本的[下個月違約繳款]取平均數,創建[教育_target_mean]新特徵。

完整程式碼