課程

在上一節萃取出文本關鍵字,但是關鍵字還需要轉換為可被分析的資料,本節會進行資料轉換的任務。一般類別型變數,像是:性別、組別等等,如果為性別變數,一般會設男生為1,女生為0這種轉換方式。
在本節關鍵字轉換的方法為,利用上一節選出文本中前N名關鍵字,本節再個別與今日新聞配對,有出現在今日新聞設為1,反之設為0。
程式碼自定義為one_hot函式,最後第8節會利用這個函式將結果跑出。
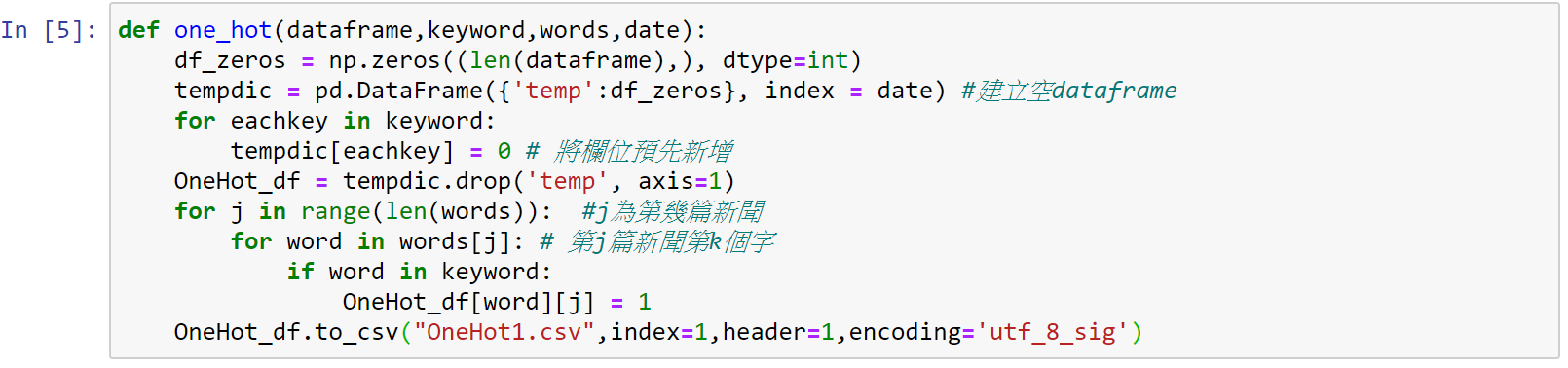
df_zeros = np.zeros((len(dataframe),), dtype=int)
利用NumPy建立陣列
np.zeros((len(dataframe),), dtype=int)建立0元素的長度為dataframe的陣列,指定資料型態為整數,如下圖所示

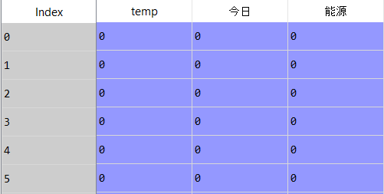
tempdic = pd.DataFrame({'temp':df_zeros}, index = date) 利用剛剛命名為df_zeros的0陣列,建立空dataframe,index為日期,如下圖所示:

for eachkey in keyword:
tempdic[eachkey] = 0
OneHot_df = tempdic.drop('temp', axis=1)
將關鍵字利用迴圈預先建立關鍵字欄位,再刪除原建立名為temp的欄位
for j in range(len(words)): #j為第幾篇新聞
for word in words[j]: # 第j篇新聞第k個字
if word in keyword:
OneHot_df[word][j] = 1
j為第幾篇新聞,words為list型態資料,存有j篇新聞中斷詞完成的字詞,將words利用迴圈放入word,如果J篇新聞的詞等於關鍵字,該關鍵字欄位則為1。
OneHot_df.to_csv("OneHot1.csv",index=1,header=1,encoding='utf_8_sig')
將OneHot_df匯出,檔案名稱為OneHot1.csv