課程

2020/08/03
模型介紹
比較三種模型算法
決策樹模型一:ID3
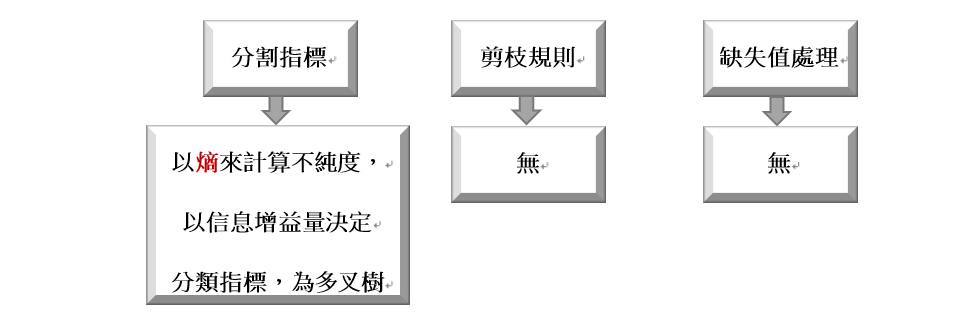
應用於資料類型為離散型之分類問題。每個有數據集的節點都能計算出其熵值,計算未分類前之熵值(稱信息熵)與分類後之熵值(稱條件熵),相減後得到信息增益量,取信息增益量最大(表不純度將低最多)之分類屬性作為分類指標且為多叉樹,可分多枝(一層可用多個指標分類)。
信息熵值-條件熵值=信息增益量
缺點:
1.因無設定剪枝規則,易有過擬合狀況。
2.此信息增益衡量標準會偏好分類較多的特徵(因一層可分多枝),使過擬合狀況加劇
決策樹模型二:C4.5
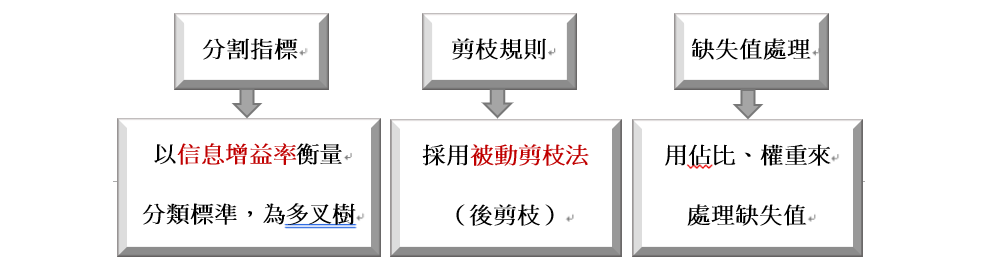
同樣應用於分類問題,但資料類型可為離散或連續型。並以信息增益率來決定分類指標。
資訊增益率 = 資訊增益 ÷ 分類屬性的分割資訊值
且引入被動剪枝法,樹生成後再由下往上檢視每個內部節點,若以葉節點取代會降低錯誤率則進行剪枝。後剪枝比起預剪枝,可降低過擬合風險,但同時訓練時間會拉長。
決策樹模型三:CART(為現今最常使用之模型)
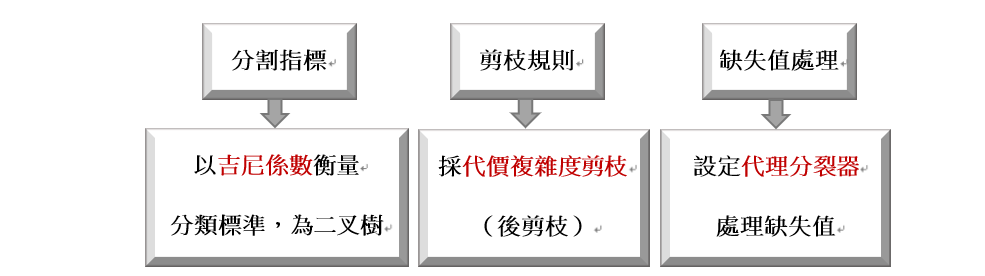
應用範圍較廣,可用於問題分類及迴歸,資料類型也可為離散及連續型。
CART使用吉尼係數(吉尼不純度)衡量分類標準,以降低運算時間。吉尼係數代表代表模型的不純度,吉尼係數越小,不純度低,特徵越好。
採用代價複雜度剪枝法,每次進行剪枝會生成一顆子樹,最後再從每棵樹中挑選最優的樹。
設定代理分裂器來處理缺失值,即從所有特徵中設定一特徵為代理分裂器,當遇到缺失值時,代理缺失值特徵。
三組模型比較
| ID3 | C4.5 | CART | |
| 樣本類型 | 離散型 | 離散型、連續型 | 離散型、連續型 |
| 應用場景 | 分類 | 分類 | 分類、回歸 |
| 分割標準 | 資訊增益(熵) | 資訊增益率 | 吉尼係數 |
| 剪枝策略 | 無 | 被動剪枝法 (後剪枝) |
代價複雜度剪枝 (後剪枝) |
| 缺失值處理 | 無 | 有 | 有 |
| 運算速度 | 慢 | 慢 | 快 |